



埃隆·马斯克耗资数十亿美元,以122天惊人的建造速度建造了一个规模宏大的AI集群——配备100,000个NVIDIA H100 GPU
这些GPU服务器采用的是Nvidia HGX H100平台,每台服务器包含八个H100 GPU。HGX H100平台装在Supermicro的4U通用液冷GPU系统内,为每个GPU提供便捷的热插拔液冷功能。这些服务器被装载在机架上,每个机架可容纳八个服务器,即每个机架64个GPU。1U冷却总管夹在每个HGX H100之间,为服务器提供必要的液冷。每个机架底部另设有Supermicro 4U单元,配备冗余泵系统和机架监控系统。
这些机架成组排列,每组八个,总计512个GPU。每个服务器配有四个冗余电源,机架后部展示了三相电源、以太网交换机及机架级总管,为所有液冷设备供电。Colossus集群中有超过1,500个GPU机架,约200组。根据Nvidia首席执行官黄仁勋的说法,安装这些200组GPU仅用了三周时间。

由于AI超级计算机集群在持续训练模型时对带宽要求极高,xAI在网络互联方面不惜重金投入。每块显卡都配备了一个400GbE的专用网络接口控制器(NIC),每个服务器还额外配备一个400Gb的NIC。这意味着每个HGX H100服务器的以太网速度可达3.6Tbps。是的,整个集群都运行在以太网上,而非超级计算领域常用的InfiniBand或其他异构连接。

当然,像 Grok 3 聊天机器人这样基于训练 AI 模型的超级计算机需要的不仅仅是 GPU ,还需要大量的CPU才能运行。因此,Colossus还配置了CPU计算服务器,其外观与Supermicro存储服务器极为相似。视频显示,这些服务器多为NVMe直通的1U服务器,采用某种x86平台CPU,配备后置液冷系统,用于存储和CPU计算。

在机房外,还看到了一些特斯拉Megapack电池组。由于集群的启停特性以及运作过程中产生的毫秒级延迟超出了电网或马斯克的柴油发电机的负荷能力,部分特斯拉Megapacks(每个储存可达3.9 MWh)用作电网和超级计算机之间的能量缓冲。

根据Nvidia的说法,xAI Colossus超级计算机目前是全球最大的AI超级计算机。与其他超级计算机主要供承包商或学术机构研究气象、疾病等复杂计算任务不同,Colossus仅用于训练X(前身为Twitter)的各类AI模型,尤其是马斯克的“反觉醒”聊天机器人Grok 3,仅面向X Premium订阅者开放。ServeTheHome透露,Colossus还在训练“未来的AI模型”,这些模型的用途和能力超出当今主流AI。
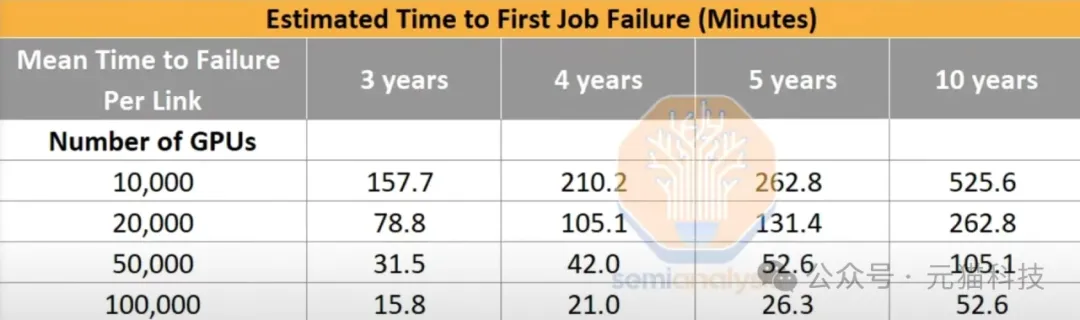
Colossus的第一阶段建设已完成,集群已全面上线,但尚未完全竣工。增加5万张H100 GPU和5万张下一代H200 GPU,GPU总数将翻倍,升级后电力需求将超出马斯克7月新增的14台柴油发电机的供电能力。这也低于马斯克承诺的Colossus内部安装30万个H200 GPU的目标,这可能是未来的第三阶段升级。
相关推荐: 令人心动的运维面试指南——offer拿到手软,包的!
虽然很多时候,面试和实践不一样 一上来就问k8s,然后一进公司根本用不着 招聘上要求运维工程师 实际上想要的是全栈、通才还便宜的工程师 如果对面试感到无从下手 宸翊互联为大家挑选了一些靠谱的面试指南 浅浅收藏一下 预祝各位拿offer拿到手软 相关推荐: 如何…