

先是10月23日语雀接近8个小时的宕机,然后11月12日阿里云全线产品崩,11月27日阿里云又崩了。27号的故障还没缓过来,11月28日nas、ack等控制台访问异常。
11月27日阿里云数据库控制台102分钟不可用,从地域看影响八大地区,从产品来看影响云原生数据库仓库、图数据库、云数据库redis、云数据库MySQL、PolarDB、ClickHouse、数据库备份等产品。


阿里云宕麻了。
无独有偶的,滴滴也经历了惊魂一夜。
11 月 27 日晚上 10 点左右截止 2023 年 11 月 28 日中午 12 点期间,滴滴发生了长达12小时的p0级bug,这场突如其来的事故,成为压倒打工人的最后一根稻草。“滴滴崩了”“全勤没了”“部分滴滴司机开始提现”“滴滴预计损失超4亿”等话题相继登上热搜。
- 网络加载异常,无法排单;
- 数据紊乱,一个订单被派到 4 个司机订单中;
- 数据展示、数据状态有误,订单取消、订单支付都出现问题;
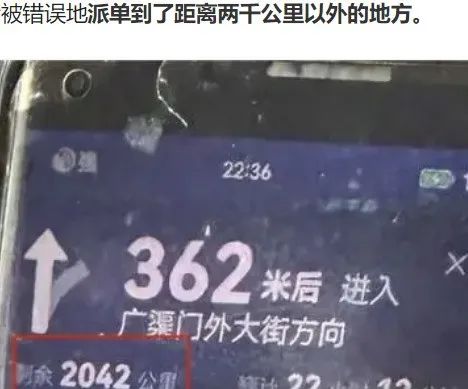
- 排单逻辑出错,司机接单到 两千公里以外的单;
- 订单流水出错,8 公里显示收费 1540 元;
- 整体问题,连带滴滴、小桔充电、滴滴加油、青桔单车都出现问题;
- 滴滴内网问题,员工无法正常使用内网相关服务;
11月28日早上,滴滴微博再次发布致歉通知,称网约车等服务已恢复,单车等还在陆续修复中。不过,直到上午9点20分,还有网友表示无法使用。对互联网大厂而言,长达十几小时的崩溃无疑是一场极大的技术事故。若粗略按照系统瘫痪12个小时估算,本次滴滴将损失约1600万订单、2.5亿元左右的营收和近4亿元交易额。
滴滴官方在微博的致歉中说是底层系统软件故障,但对于滴滴真实系统故障的原因有多方猜测。
有互联网从业者在社交平台爆料称,是滴滴系统半夜被攻击所致。“服务器没有物理隔离,物理攻击后台服务全挂,dc都上不去。”
对此,有资深IT技术总监分析,从表现上看,打车、共享单车全挂,不同的业务板块之间应该是有隔离的,说明问题出在更加底层的基础设施。“攻击者一般只能访问到应用层,基础设施访问不到的。要么是被攻击者打穿,要么是自己系统操作不慎挂了。即便是前者,也算是一种系统缺陷,才会被打穿。”
“这种一般是做更新、运维时把云底座、基础设施带崩了,滴滴历史上多次内部更新时崩溃的。异地多活容灾似乎也没起作用。”一位接近滴滴的IT人士透露。类似故障情况在 2022 年 9 月 22 日也曾出现过。当日滴滴出行官方微博致歉称由于机房网络故障,导致滴滴部分服务受影响。然而像今天这样大面积、长时间的故障,应该是滴滴史上少有的。以目前情况来看,大家还无法确认故障原因。有技术专家感慨于修复时间太长,表示“是时候废弃微服务了,别觉得自己水平多高,看看今天的滴滴吧。”
据悉,目前滴滴采用的是腾讯云服务和阿里云服务。美股公告曾显示,滴滴向腾讯采购支付处理服务、托管服务及云服务2018年、2019年和2020年的成本费用约32.6亿元;滴滴向阿里巴巴采购云服务及信息技术平台服务2018年、2019年和2020年的成本费用约32.6亿元。
腾讯也赶上了这波潮流。
12月3日,#腾讯视频崩了##腾讯会员 没了#相继冲上热搜。有部分网友反映,自己在腾讯视频充值的会员显示不存在了,想观看会员频道影片也无法观看。
还有网友表示,腾讯视频崩了,会员都没了,网名也变成腾讯网友了。

还有网友表示,首页无法加载内容。
@腾讯视频 紧急回应称:“目前腾讯视频出现了短暂技术问题,我们正在加紧修复,各端均在逐步恢复中。感谢您的耐心等待,由此给您带来的不便我们深感歉意。 ”
针对近期大厂们接连出现的报障事故,网上热议的角度也五花八门。
最广泛的还是打工人惺惺相惜打工人,群嘲降本增笑到了深水区,一不小心向社会输送真人才了。
据公开数据可以看到,阿里员工数据,今年9月30日、6月30日、3月31日,以及去年12月31日,几个时间点的员工人数分别为 224,955、228,675、235,216、239,740。9个月时间,员工人数少了1.5万人,按照这个态势下去,估计全年会减少2 万人。
根据滴滴财报,21年底,滴滴员工总数24396人,22年底是20870人,累计减少3526人。裁减比例是14.4%。相比阿里云之前裁员7%,滴滴裁员比例的确有点大。而且,滴滴研发人员占员工总数比重是40%,光2022年一年,就裁掉1090研发人员。
有些技术扎实的人才,确实职位不高,也不太会搞人际关系,平时体现不出来,但被裁撤以后,系统一直崩,新人根本玩不转。虽然不至于没人顶得上,但是不是随时都能顶上的。而醉心ppt文化的企业,哪有时间认真思考技术决策,程序就可能越写越乱,相互冲突,相互耦合,难以维护,容易出问题,而且出了问题不好解决,当这个情况累计到一定的程度,问题就开始猛烈而频繁地爆发出来了。
开猿节流更大的危害在于互联网企业从此都失去了长期规划的能力,大部分人只会为短期kpi负责(毕竟3-5年后人都不在了)。无辜受害的使用云产品的企业,对云的信任进一步降低。那些卖力宣传的自主云难道就是这个水平?如果降本增效就导致系统可用性下降,那些鼓吹各种自动化能力是不是虚的?要不要把之前自有的Redis集群再搞起来?要不要试试多云部署?最近的下云潮流要不要跟?阿里云11月份还有两次较小规模的局部故障,到今天都没有一份像样的复盘分析报告,而这种故障频率即使是对于草台班子来说也有些过份了。某种意义上说,阿里云这种周爆频率可以凭一己之力,毁掉用户对公有云云厂商的托管服务的信心。作为云服务的核心 —— 管控服务如果是这个稳定性水平,花十几倍到上百倍的资源溢价来买云上的托管资源,该崩的依旧崩,不如直接去移动联通机房租个机柜,雇两个大厂SRE,买服务器用开源软件自建。还有一部分运维从业的技术人员提出了要重视基础设施运维的工程师的重要性。相比做’主要赚钱业务‘的工程师收入相对较少,公司不论是物质资源、战略重视度倾斜都更偏业务。这块和安全部门在大公司的境遇类似,出了事儿,才能被证明价值,才会被人想起来。做基础设施的工程师要求往往比做业务的要更难。大型互联网公司出问题短时间无法解决,通常都是底层软件变动或者硬件故障。特点是难以快速定位和快速解决问题。现在大型互联网公司上层服务的高可用通常比较完善,但是底层应用的高可用似乎还有待加强。对于底层软件变动,应该慎之又慎,每次变动应该做好影响面评估,对于影响面较大的或者不可逆的操作,应该着重做好 review;需要考虑通过冗余和切流等方式提高可用性,降低变更的影响;要特别重视底层软件故障的监测机制。总之,近期经历这些不确定崩溃后,各位企业开始好好算起了一笔账。楼下饭店老板鼓吹:自己做什么饭啊?又麻烦又不省钱,来我这儿吃吧,省时省力,综合成本比你自己做的合算!饭店的食物安全健康吗?真的划算吗?上云还是下云?买房还是租公寓?降本还是变相增本?如何合理分配云上和云下资源比例,或许是未来企业探索数据安全和业务成本的重要课题。