

昨天,“报丧太监”微博大报特报“阿里云全线产品崩了“,相继,淘宝崩了、淘宝又崩了、闲鱼崩了、钉钉崩了等相继冲上热搜。


而且很可能不是一般的“崩了”,根据当前获知的信息来看,很可能是刷新历史级的“崩了”。双11当晚,淘宝曾有短暂宕机,但很快就过去了。但到了12日傍晚,包括淘宝、闲鱼、钉钉、阿里云盘、饿了么、天猫精灵、菜鸟、夸克、语雀等,多个阿里系App出现无法访问或服务异常的情况。


最无语的应该是语雀了。上个月,也就是10月23日,阿里旗下的产品“语雀”也发生了“P0”级事故,导致平台无法正常访问和使用,持续了近8个小时(14时10分至21时45分左右)。上次事件中,语雀向用户赠送了半年的会员作为补偿,不知道这次是否会有类似的补偿措施。

受影响的区域:
华北2(北京)、华北6(乌兰祭布)、华北1(青岛)、华东2(上海)、华南2(河源)、华北3(张家口)、中国香港、印度(孟买)、美国(硅谷)、华南1(深圳)、英国(伦教)、韩国(首尔)、日本(东京)、阿联酋(迪拜)、西南1(成都)、华南3 (广州)、新加坡、澳大利亚(悉尼)、马来西亚(吉隆坡)、华北5(呼和浩特)、印度尼西亚 (雅加达)、美国(弗吉尼亚)、菲律宾(马尼拉)、泰国(曼谷)、华东1(杭州)、华南1金融云。
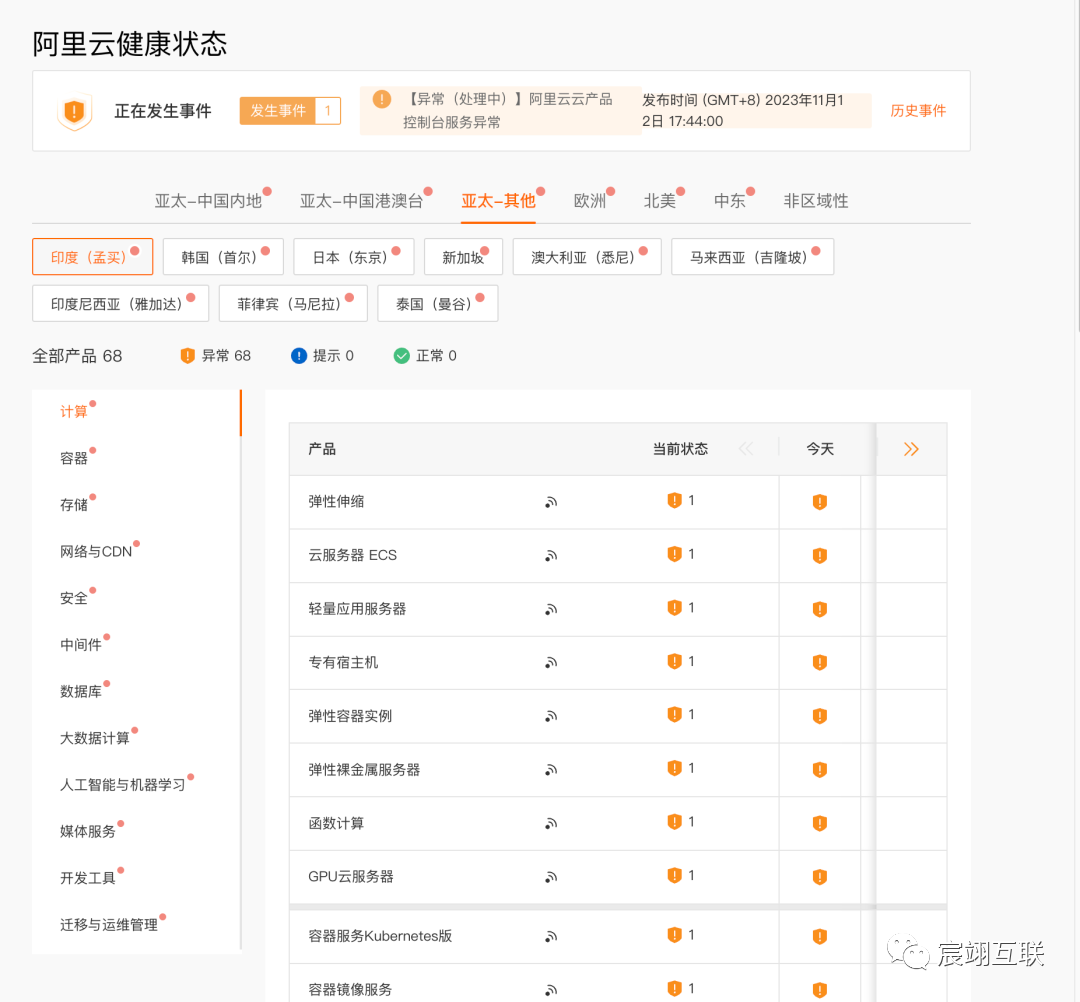
从阿里云的健康状态页(Status Page)的信息看,这不是某个可用区的故障,而很可能是全球大故障,几乎没有幸免的区域,受影响的不光是阿里云自有的业务区域,还包括对外服务的金融云,政务云。更严峻的是,没有一个幸免的服务,清一色全挂。
事件回顾(故障三个半小时 (17:44 – 21:11 )
17:44阿里云确认故障原因与某个底层服务组件有关,工程师正在紧急处理中。
18:54经过工程师处理,杭州、北京等地域控制台及API服务已恢复,其他地域控制台及API服务逐步恢复中。
19:20工程师通过分批重启组件服务,绝大部分地域控制台及API服务已恢复。
19:43异常管控服务组件均已完成重启,除个别云产品(如消息队列MQ、消息服务MNS)仍需处理,其余云产品控制台及API服务已恢复。
20:12北京、杭州等地域消息队列MQ已完成重启,其余地域逐步恢复中。
21:11受影响云产品均已恢复,因故障影响部分云产品的数据(如监控、账单等)可能存在延迟推送情况,不影响业务运行。

有行业从业者表示,对于阿里云此次故障感到十分震撼,因为其从业以来还没听说过这种规模的云计算故障。当前各个技术群里充满着焦虑愤怒,因为这种情况下,用户的自救可能性为零,只能等待阿里云恢复。
而由于阿里云的市场份额巨大,就在十几天前的2023云栖大会上,阿里巴巴集团主席蔡崇信曾指出,目前中国80%的科技企业和一半的大模型公司都跑在阿里云上,此次故障造成的影响面非常大。
云上产品开始渗透到我们生活方方面面,对此,受到影响的网友纷纷加入双十一混战吐槽:

而同行也毫不客气调侃起来阿里降本增笑 初见成效。本次事故的表象是技术故障,但是维护系统的始终还是人。这次阿里云大面积故障的深层原因大概率源于8月份的大规模裁撤大龄员工。
初见成效。本次事故的表象是技术故障,但是维护系统的始终还是人。这次阿里云大面积故障的深层原因大概率源于8月份的大规模裁撤大龄员工。
从阿里云的角度看,这次故障很“不阿里云”,毕竟阿里云一向以安全稳定高可用自居,如此大范围、如此长时间、影响面如此广的故障,对阿里云的品牌形象绝对是致命的打击,这已经不是“杀一个程序员祭天”就能了事的,很可能需要“杀一个CEO”,但遗憾的是,阿里云现在并没有CEO。更头疼的是,后面还要面对漫天如同雪花般的赔偿诉求。
从员工角度
接连出事,原来降本增效、开猿节流的福报又得被迫释放人才了
年终奖没了是小,扣工资更有可能
至少会拿个P0祭天
懂事的阿里人已经开始写简历了
从客户角度
之前字节中午全线崩一个小时,损失2个小目标
这次阿里云双十一期间崩,根据SLA99.99%,一小时就是10%赔偿
未来更面临订单变化
阿里云不再是高性能、高可用的代名词了
经此一役客户对阿里云的迷信很可能将破灭
从品牌角度
AWS、华为云、腾讯云等敌蜜已经摩拳擦掌
有句老话”趁你病,要你命“
血洗一波客户更在待何时
从网安角度
其实最近接连出现网安故障的还有ChatGPT,同日下午,ChatGPT和其他一些服务出现故障,正在调查各种服务宕机原因。随后,OpenAI表示,故障问题解决,现已正常运行。早在周四,ChatGPT发现了受到DDoS攻击的迹象(DDOS是(Distributed Denial of Service)的缩写,即分布式阻断服务,黑客利用DDOS攻击器控制多台机器同时攻击来达到“妨碍正常使用者使用服务”的目的。早在11月9日,OpenAI的ChatGPT和API服务出现严重中断故障,导致面向用户和开发者的服务无法正常使用。在随后的16个小时里,ChatGPT仍未完全恢复。
因此,任何服务都不可靠,增强底层服务组件的容灾能力,异地多活、多机房部署、甚至多云部署,“有备无患”。